Let's dive deeper into how large language models might evolve to large reasoning model:
Tokenization: The input text is broken down into individual units – tokens. These can be words, subwords (parts of words), or even characters.Contextual Embedding Layer: This is where the magic happens. Each token is converted into a vector (a list of numbers) called acontextual embedding . Crucially, this embedding is not fixed; it depends on thesurrounding words. So, the same word can have different embeddings depending on the context it appears in. For example, the word "bank" will have a different embedding in the sentence "I sat by the river bank" compared to "I went to the bank to deposit money." This context-sensitive embedding is what allows the model to understand nuances in language.Decoder Block: This part of the model takes the contextual embeddings as input and uses them to predict the probability of each possible next word/token. It considers all the words in its vocabulary and assigns a probability to each one, based on how well it fits the current context. The word with the highest probability is selected as the next word in the sequence.


Reasoning Tokens: These special tokens act as prompts to guide the model's thinking process. They can be natural language phrases or specific symbols that signal reasoning steps. For instance, reasoning tokens might start with "Therefore," "Because," or "Step 1:".Benefits of Chain-of-Thought: This approach improves performance on complex reasoning tasks by forcing the model to decompose the problem into smaller, more manageable steps. It also makes the model's reasoning more transparent and interpretable.

Reasoning Embedding Layer: This new layer learns to encode the essence of the reasoning process directly into the embeddings. Instead of explicitly generating reasoning steps, the model incorporates the learned reasoning patterns into its prediction process.Efficiency Gains: By eliminating the need to generate intermediate tokens, this approach reduces computational cost and speeds up text generation.
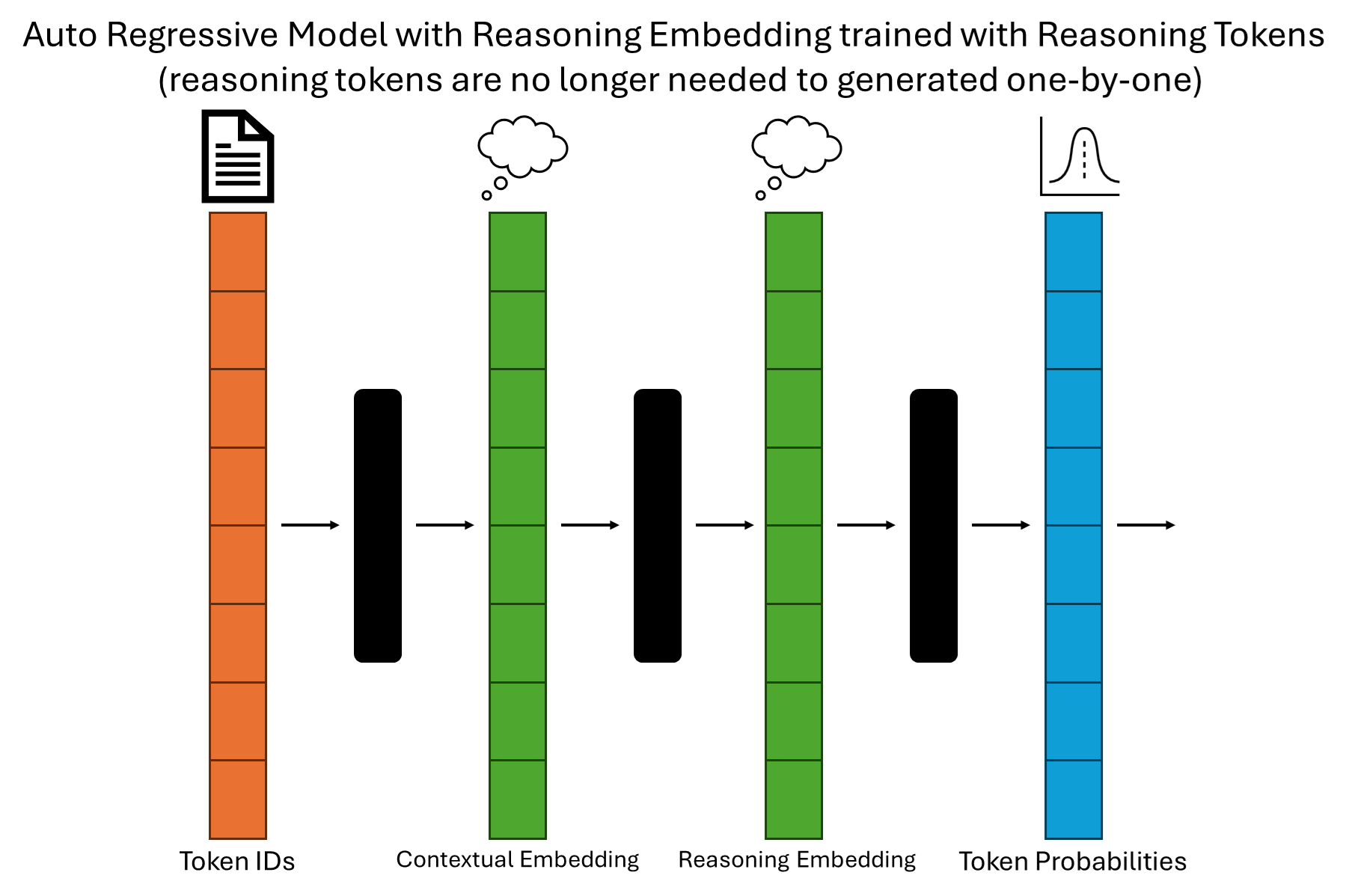
As large language models evolve into powerful reasoning engines, we stand on the brink of a new era in AI capabilities. From foundational autoregressive models to innovative reasoning embeddings, each step forward enhances the efficiency, interpretability, and complexity of what these models can achieve. By integrating explicit reasoning (reasoning tokens) and implicit reasoning (reasoning embeddings) mechanisms, the future promises not only faster and more accurate text generation but also models capable of deeper understanding and problem-solving.