Large Language Models (LLMs) have captivated the world with their ability to generate human-like text, translate languages, answer questions, and even write code. However, beneath the surface of impressive fluency lies a fundamental limitation: a struggle with true generalization and logical reasoning. While LLMs can mimic reasoning processes, they often fall short when confronted with tasks requiring genuine understanding, extrapolation beyond observed patterns, or the application of logical principles. This article delves into the architectural and training-related reasons behind these limitations.
The Autoregressive Bottleneck: A Word-by-Word Worldview
Local Optimization vs. Global Reasoning: The autoregressive model excels at identifying and replicating statistical patterns within its training data. Each word is chosen to minimize immediate prediction error, akin to a myopic traveler always selecting the next closest city without considering the overall journey. This leads to difficulties in tasks requiring holistic understanding or logical coherence across an entire text. The analogy of the traveling salesman problem perfectly illustrates this; the algorithm minimizes the cost at each step but doesn't necessarily find the globally optimal route.The Chinese Room Argument Reimagined: Philosopher John Searle's Chinese Room argument challenges the notion that manipulating symbols according to rules equates to genuine understanding. LLMs, in their current form, operate much like the person in the Chinese Room. They can process and generate text by following statistically derived rules (encoded in their massive weight matrices), but this doesn't necessarily mean they comprehend the meaning or possess the ability to reason about the information.Error Propagation and the Fragility of Reasoning Chains: The sequential nature of autoregressive models makes them highly susceptible to error propagation. A single incorrect word prediction can cascade into a series of errors, derailing the entire generation process. This is particularly problematic in tasks requiring multi-step reasoning, where a flawed premise can invalidate the entire chain of thought, even if subsequent steps are logically sound. While techniques like "chain-of-thought" prompting encourage LLMs to articulate intermediate reasoning steps, they remain vulnerable to this cascading effect. A wrong "thought" leads to an incorrect overall conclusion.
Training Limitations: Statistical Patterns vs. Logical Principles
Self-Supervised Pretraining: Learning Correlations, Not Causation: LLMs are typically pretrained on massive text corpora using self-supervised learning, where the model learns to predict masked or subsequent words. While this allows them to acquire a vast amount of linguistic and factual knowledge, it primarily captures statistical correlations between words, not causal relationships or logical principles. The model learns what words tend to co-occur, but not necessarilywhy they co-occur or the logical connections between them. This explains why early GPT models, while fluent, often produced nonsensical or factually incorrect outputs.The Specialization Tradeoff of Supervised Fine-tuning: Instruction tuning and Reinforcement Learning from Human Feedback (RLHF) refine LLMs to better align with human expectations and follow instructions. However, this supervised learning process introduces a form of specialization, akin to training a skilled craftsman in one particular area. While this enhances performance on specific tasks seen during training, it can hinder generalization to novel or unseen scenarios. The model becomes adept at solving problems similar to those it has encountered before, but struggles with tasks outside its "comfort zone," as evidenced by failures on simple tasks like counting characters in a word if such tasks are uncommon in training data.The Long Tail Problem: Skewed Performance and Unseen Scenarios: Even with multi-task training, LLMs face the "long tail" problem. They perform well on tasks that are well-represented in the training data but often fail on rare or unusual tasks. This is because statistical learning models are fundamentally limited by the distribution of the data they are trained on. They can interpolate and extrapolate within the bounds of observed patterns, but struggle with tasks that deviate significantly from those patterns.
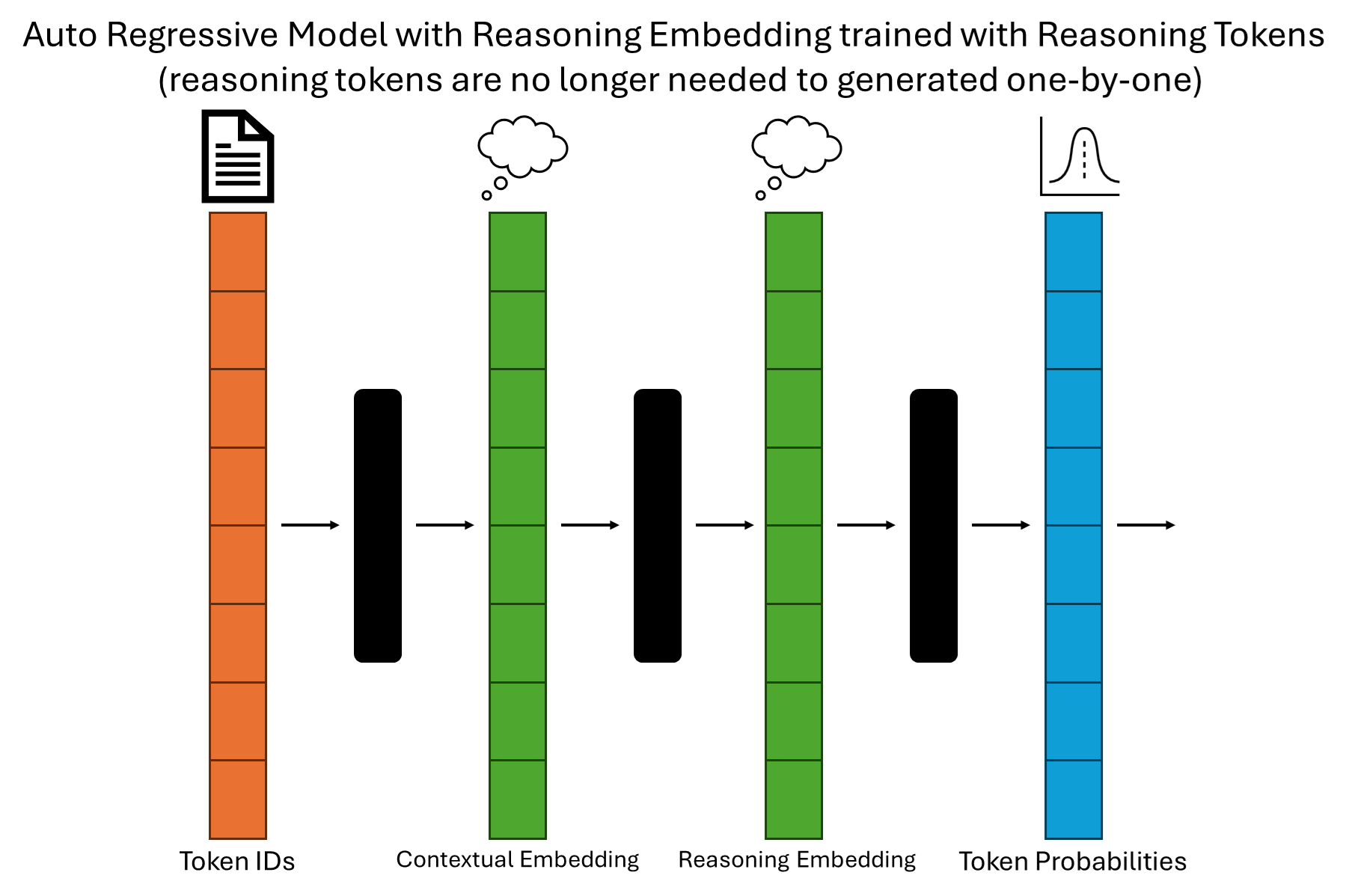
Reasoning Tokens: A Superficial Facade?
Imitating System 2 Thinking without the Underlying Mechanisms: The goal is to simulate "System 2" thinking, characterized by deliberate and logical reasoning, as opposed to the intuitive "System 1" thinking. However, LLMs achieve this by generating text thatresembles step-by-step reasoning, not by actually engaging in logical deduction, induction, or abduction. The model is still fundamentally predicting the next token based on statistical patterns; it's simply conditioned on a prompt that encourages a more verbose and structured output.Vulnerability to Surface-Level Cues and Biases: LLMs remain susceptible to surface-level cues and biases present in the training data. They can be easily misled by irrelevant information or subtle changes in phrasing, leading to illogical or incorrect conclusions, even when they appear to be "reasoning" correctly. This highlights the lack of deep understanding and robust reasoning capabilities.